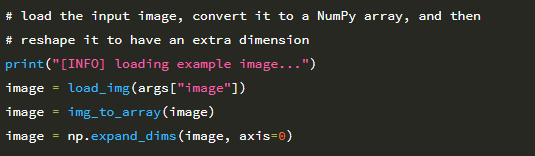
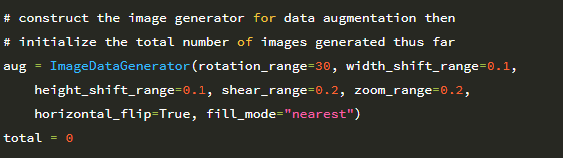
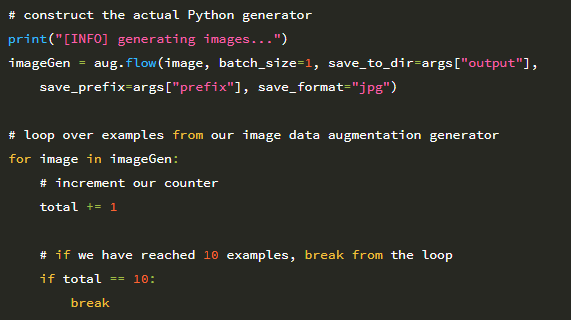
시작하려면 Flowers-17 데이터 세트에서 MiniVGGNet 아키텍처 (16 장)를 학습 할 때 데이터 증가를 사용하지 않는 기준을 설정해 보겠습니다. 새 파일을 열고 이름을 minivggnet_flowers17.py로 지정하면 작업을 시작할 수 있습니다.
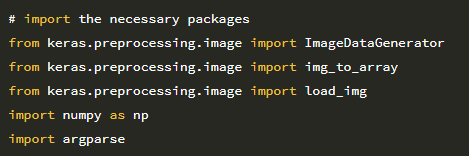
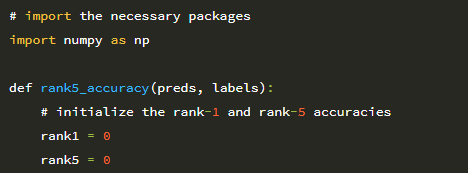
2 ~ 14 행은 필수 Python 패키지를 가져옵니다. 이전에 본 대부분의 import는 다음과 같습니다.
1. 6행 : 여기에서 새로 정의 된 AspectAwarePreprocessor를 가져옵니다.
2. 7 행 : 별도의 이미지 전처리기를 사용 함에도 불구하고 SimpleDatasetLoader를 사용하여 디스크에서 데이터 세트를로드 할 수 있습니다.
3. 8 행 : 데이터 세트에서 MiniVGGNet 아키텍처를 학습합니다.
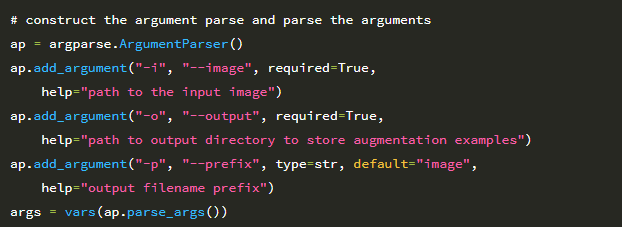
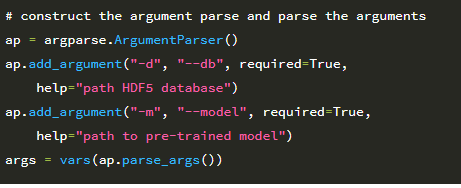
다음으로 명령 줄 인수를 구문 분석합니다.
여기에는 디스크에있는 Flowers-17 데이터 세트 디렉토리의 경로 인 –dataset이라는 단일 스위치 만 필요합니다.
계속해서 입력 이미지에서 클래스 레이블을 추출해 보겠습니다.
Flowers-17 데이터 세트는 다음과 같은 디렉토리 구조를 가지고 있습니다.
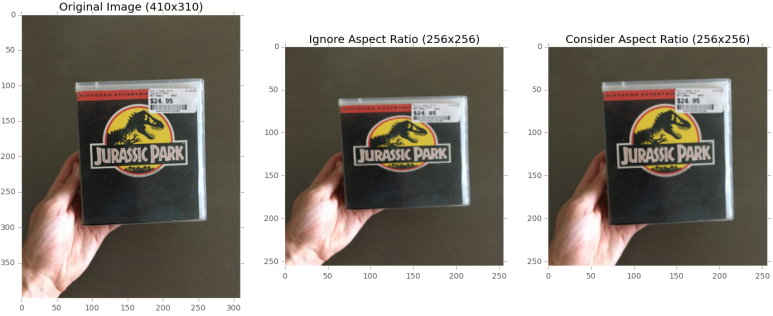
데이터 세트의 이미지 예는 다음과 같습니다.
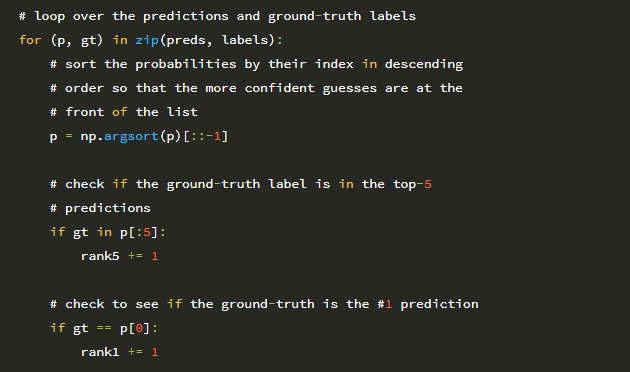
따라서 클래스 레이블을 추출하기 위해 경로 구분 기호 (26 행)를 분할 한 후 두 번째에서 마지막 인덱스를 추출하여 bluebell 텍스트를 생성 할 수 있습니다. 이 경로 및 레이블 추출이 어떻게 작동하는지 확인하는 데 어려움을 겪는 경우 Python 셸을 열고 파일 경로 및 경로 구분 기호를 사용하는 것이 좋습니다. 특히 운영 체제의 경로 구분 기호를 기반으로 문자열을 분할 한 다음 Python 인덱싱을 사용하여 배열의 다양한 부분을 추출하는 방법에 유의하십시오.
그런 다음 27 행은 이미지 경로에서 고유 한 클래스 레이블 집합 (이 경우 총 17 개의 클래스)을 결정합니다. imagePaths가 주어지면 디스크에서 Flowers-17 데이터 세트를 로드 할 수 있습니다
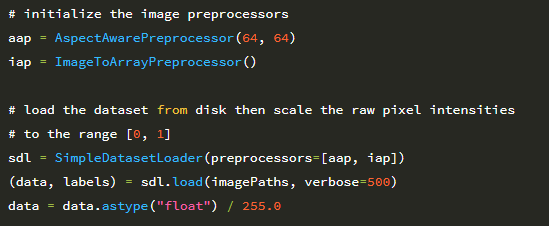
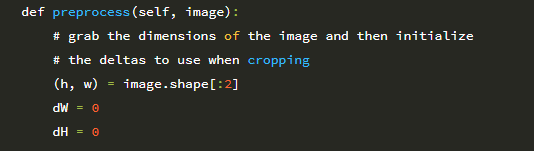
30 행은 AspectAwarePreprocessor를 초기화하여 처리하는 모든 이미지가 64×64 픽셀이되도록 합니다. 그러면 ImageToArrayPreprocessor가 31 행에서 초기화되어 이미지를 Keras 호환 배열로 변환 할 수 있습니다. 그런 다음 각각이 두 전처리기를 사용하여 SimpleDatasetLoader를 인스턴스화합니다 (35 행).
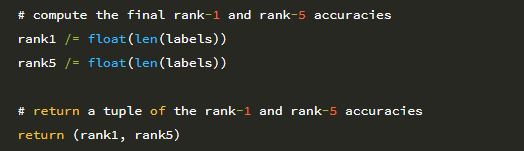
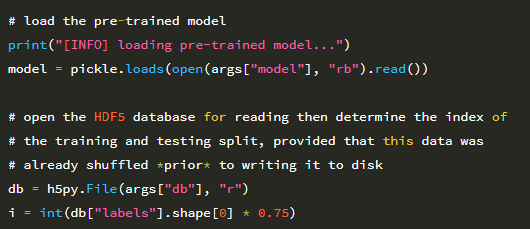
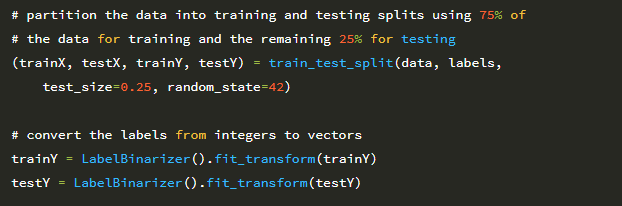
데이터 및 해당 레이블은 36 행에서 디스크에서 로드됩니다. 그런 다음 데이터 배열의 모든 이미지는 원시 픽셀 강도를 255로 나누어 [0,1] 범위로 정규화됩니다. 이제 데이터가 로드 되었으므로 학습을 수행 할 수 있습니다. 라벨을 원-핫 인코딩과 함께 테스트 분할 (학습용 75 %, 테스트 용 25 %) 합니다.
꽃 분류기를 훈련하기 위해 SGD 최적화 프로그램과 함께 MiniVGGNet 아키텍처를 사용합니다.
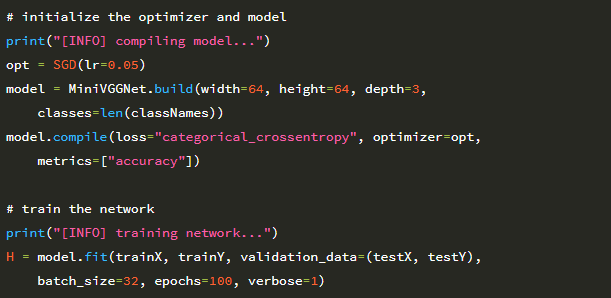
MiniVGGNet 아키텍처는 64 × 64 × 3 (너비 64 픽셀, 높이 64 픽셀, 채널 3 개)의 공간 크기 이미지를 허용합니다. 총 클래스 수는 len (classNames)이며,이 경우 Flowers-17 데이터 세트의 각 카테고리에 대해 하나씩해서 17 개입니다.
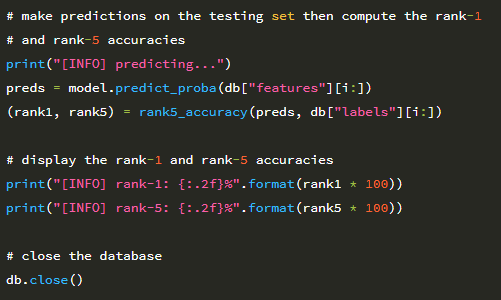
초기 학습률 α = 0.05로 SGD를 사용하여 MiniVGGNet을 훈련합니다. 다음 섹션에서 데이터 증가가 미치는 영향을 입증 할 수 있도록 의도적으로 학습률 감소를 제외 할 것입니다. 58 행과 59 행은 MiniVGGNet을 총 100 epoch 동안 훈련합니다. 그런 다음 네트워크를 평가하고 시간에 따른 손실과 정확도를 플로팅합니다.
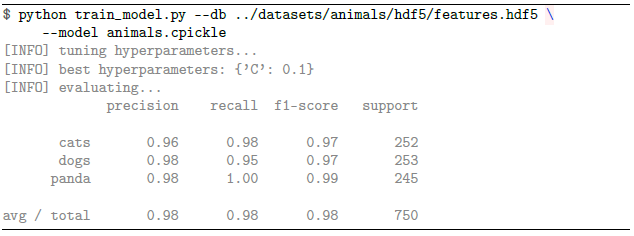
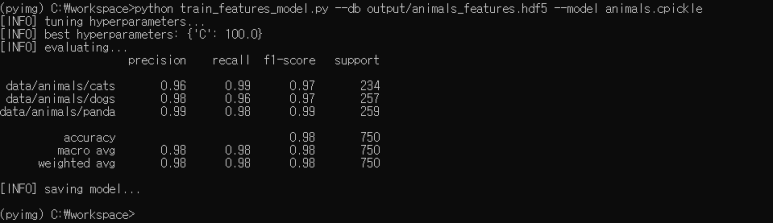
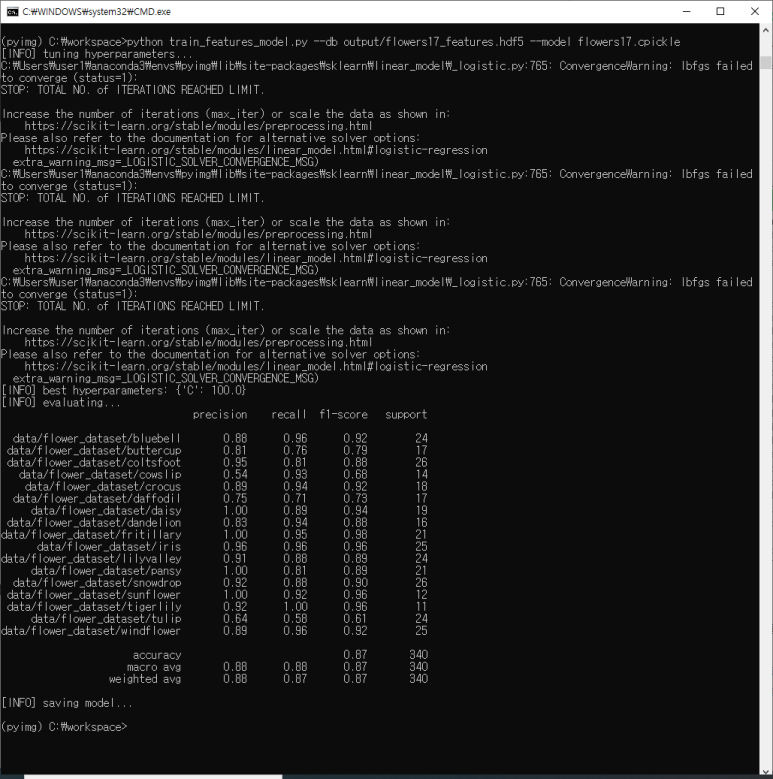
MiniVGGNet을 사용하여 Flowers-17에 대한 기준 정확도를 얻으려면 다음 명령을 실행하십시오.


출력에서 볼 수 있듯이, 제한된 양의 훈련 데이터를 고려할 때 상당히 합리적인 64 %의 분류 정확도를 얻을 수 있습니다. 그러나 우려되는 것은 손실 및 정확도 플롯입니다 아래 그림에서 알 수 있듯이 네트워크는 Epoch 20을 지나서 빠르게 과적합 되기 시작합니다. 이유는 클래스 당 60 개의 이미지가있는 1,020 개의 학습 예제 만 있기 때문입니다 (다른 이미지는 테스트에 사용됩니다.) Convolutional Neural Network를 훈련 할 때 클래스 당 1,000-5,000 개의 예제가 이상적으로 있어야한다는 점을 명심하십시오.
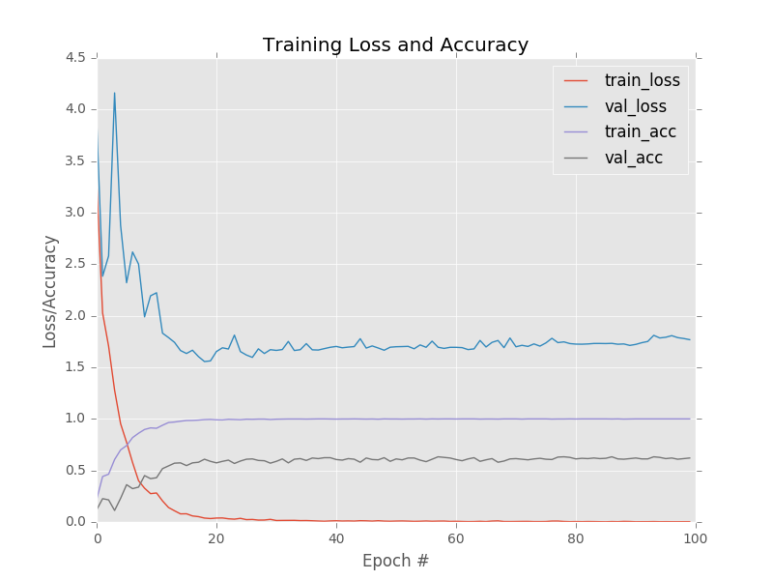
데이터 증대없이 Flowers-17 데이터 셋에 적용된 MiniVGGNet의 학습 플롯. 검증 손실이 증가함에 따라 epoch 25 이후에 과적 합이 어떻게 시작되는지 주목하십시오.
더욱 이 훈련 정확도는 처음 몇 epoch에서 95 %를 초과하여 급등하여 결국에는 100 % 정확도를 얻습니다.이 출력은 과적합의 분명한 경우입니다. 상당한 학습 데이터가 부족하기 때문에 MiniVGGNet은 학습 데이터의 기본 패턴을 너무 가깝게 모델링하고 테스트 데이터로 일반화 할 수 없습니다.
과적합을 방지하기 위해 정규화 기술을 적용 할 수 있습니다.이 장의 맥락에서 정규화 방법은 데이터 증가입니다. 실제로는 과적합의 영향을 더 줄이기 위해 다른 형태의 정규화 (weight decay, 드롭 아웃 등)도 포함 됩니다.